Оптимизация OpenSearch под размер шарда - важный компонент для достижения максимальной производительности вашего кластера.
Шарды OpenSearch позволяют распараллелить обработку данных как на одном узле, так и на нескольких узлах OpenSearch.
OpenSearch автоматически управляет распределением шардов между узлами. Однако выбор необходимого количества шардов остается за пользователем.
Структура кластера OpenSearch
Для начала давайте рассмотрим структуру кластера OpenSearch.
Во-первых, мы используем как минимум три узла. Распределенные системы, такие как OpenSearch, могут столкнуться с проблемой «раздвоенного мозга». При «раздвоении мозга» два разных узла могут претендовать на роль хозяина. Третий узел необходим для того, чтобы нарушить равновесие и выбрать, какой узел является ведущим.
Во-вторых, каждый шард должен иметь хотя бы одну реплику. В случае сбоя узла вам понадобится дубликат данных для шарда (шардов), хранящийся на автономном узле, чтобы предотвратить потерю данных.
И наконец, реплика должна храниться на другом узле, чем соответствующий шард. Это необходимо потому, что если узел выйдет из строя, то вы хотите, чтобы реплики были доступны на другом, онлайн-узле.
OpenSearch справляется с разделением шардов и их соответствующих реплик на разные узлы. Это не нужно настраивать вручную.
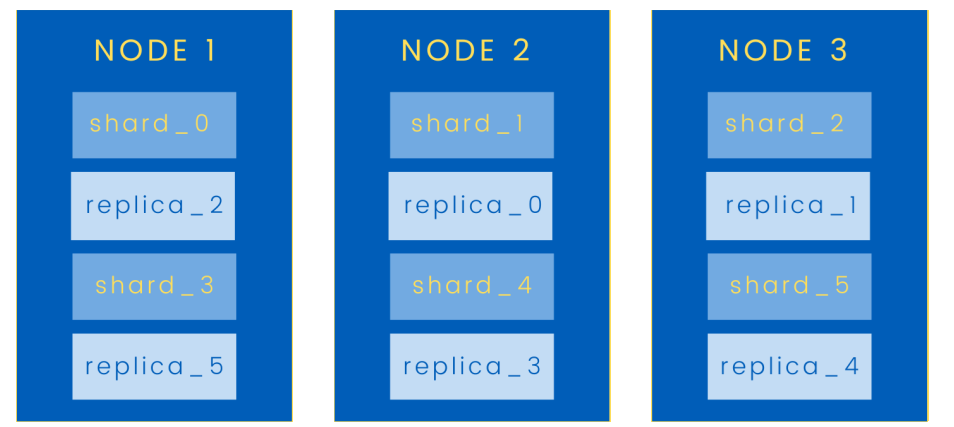
На рисунке выше мы привели изображение этой структуры кластера Opensearch. На узле 1 хранится shard_0, а его реплика, replica_0, находится на узле 2.
Аналогично, shard_1 хранится в узле 2, а его реплика - в узле 3.
Шард может иметь столько реплик, сколько вы хотите. Мы рекомендуем использовать как минимум одну реплику. А для важной или конфиденциальной информации может быть рекомендовано несколько реплик.
Теперь, когда мы рассмотрели структуру кластера OpenSearch, давайте приступим к решению вопроса о том, сколько шардов необходимо.
Каждый шард использует ресурсы
Определение распределения шардов с самого начала очень важно. Корректировка количества шардов после запуска кластера в производство требует переиндексации всех исходных документов. А переиндексация - это долгий процесс.
Возможно, вы думаете: «Давайте выделим безумно большое количество шардов». К сожалению, это дорогостоящий и неэффективный подход.
Каждый шард использует ресурсы памяти и процессора.
Кроме того, каждый поисковый запрос требует взаимодействия с каждым шардом в индексе. Если шарды конкурируют за одни и те же аппаратные ресурсы, то лишние шарды будут снижать производительность.
Подробнее о том, как индексировать OpenSearch, читайте здесь.
Расчет необходимого количества шардов
В идеале максимальный размер шарда должен составлять 30-80 ГБ. Но один шард может вмещать до 100 ГБ и при этом работать хорошо.
Используя значение 30-80 ГБ, вы можете рассчитать, сколько шардов вам понадобится.
Например, предположим, что вы ежемесячно ротируете индексы и ожидаете около 600 ГБ данных в месяц. В этом случае вам потребуется от 8 до 20 шардов.
Для общей производительности лучше использовать меньшее количество больших шардов, а не большое количество маленьких. Это связано с тем, что каждый шард будет занимать ограниченное количество ресурсов.
В приведенном выше примере мы, скорее всего, будем придерживаться нижней границы диапазона и использовать около 10 шардов.
Конечно, бывают и исключения.
Допустим, ваш сценарий использования ориентирован на индексирование с низкой задержкой, быстрые запросы, и у вас 40 узлов. В этом случае мы увеличим количество шардов до 40, чтобы лучше распределить шарды по оборудованию за счет менее эффективного распределения шардов.
При общем количестве 40 шардов каждый из наших узлов будет обрабатывать 1/40 часть данных, в то время как при 8 шардах 8 узлов будут обрабатывать 1/8 часть данных, а остальные 32 узла не будут ничего делать.