Elasticsearch чрезвычайно масштабируем благодаря своей распределенной архитектуре. Одной из причин этого является то, что называется шардингом. Если вы раньше работали с другими технологиями, такими как реляционные базы данных, то, возможно, вы слышали этот термин.
Прежде чем перейти к рассмотрению того, что такое шардинг, давайте сначала поговорим о том, зачем он вообще нужен. Предположим, что у вас есть индекс, содержащий множество документов общим объемом 1 терабайт данных. В вашем кластере есть два узла, на каждом из которых доступно 512 гигабайт для хранения данных. Очевидно, что весь индекс не поместится ни на одном из узлов, поэтому необходимо как-то разделить данные индекса, иначе мы останемся без дискового пространства.
В подобных сценариях, когда размер индекса превышает аппаратные ограничения одного узла, на помощь приходит шардинг. Шардинг решает эту проблему путем разделения индексов на более мелкие части, называемые шардами. Таким образом, шард содержит подмножество данных индекса и сам по себе является полностью функциональным и независимым, и вы можете считать, что шард - это "независимый индекс". Это не совсем точно, поэтому я и взял это слово в кавычки, но, тем не менее, это хороший способ подумать об этом. Когда индекс разделен на осколки, данный документ в этом индексе будет храниться только в одном из осколков.
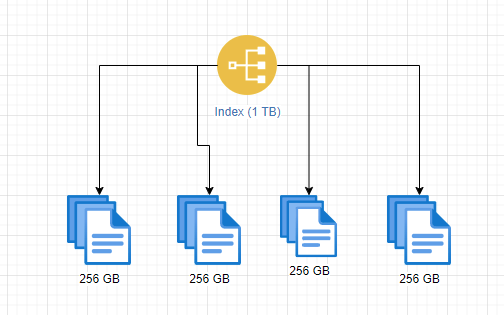
Самое замечательное в шардах то, что они могут быть размещены на любом узле кластера. При этом осколки индекса не обязательно будут распределены по нескольким физическим или виртуальным машинам, поскольку это зависит от количества узлов в кластере. Так, в предыдущем примере мы можем разделить индекс объемом 1 терабайт на четыре осколка, каждый из которых содержит 256 гигабайт данных, и эти осколки можно распределить между двумя узлами, что означает, что индекс в целом теперь помещается на доступном нам дисковом пространстве.
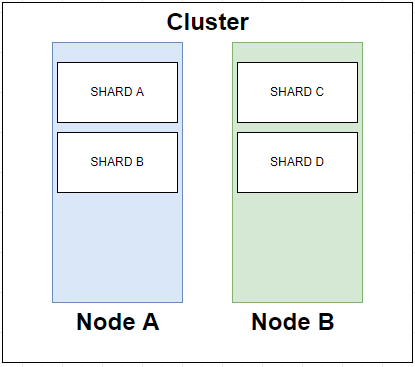
Есть две основные причины, по которым важно использовать шардинг, первая из которых заключается в том, что он позволяет разделить и тем самым масштабировать объемы данных. Таким образом, если у вас растут объемы данных, вы не столкнетесь с узким местом, поскольку всегда можете изменить количество шардов для конкретного индекса.
Другая причина важности шардинга заключается в том, что операции можно распределить по нескольким узлам и тем самым распараллелить их. Это приводит к увеличению производительности, поскольку несколько машин могут потенциально работать над одним и тем же запросом. Это совершенно прозрачно для вас как пользователя Elasticsearch.
Как же указать количество осколков в индексе? При желании вы можете указать это при создании индекса, но если вы этого не сделаете, то по умолчанию будет использоваться число 5. В большинстве случаев этого достаточно, так как это позволяет увеличить объем данных, прежде чем вам придется беспокоиться о добавлении дополнительных шардов. Сколько времени пройдет, прежде чем вам придется беспокоиться об этом, зависит от объема данных, хранящихся в конкретном индексе, и от имеющегося у вас оборудования, то есть от количества узлов и объема дискового пространства. Конечно, в игру вступают и другие индексы с их объемом данных, поэтому то, сколько осколков вам нужно, зависит от нескольких факторов. Тем не менее, по умолчанию используется 5 шардов, и вам не придется долго разбираться с шардингом, если только вы уже не работаете с большими объемами данных.
Но что делать, если вам нужно изменить количество шардов для индекса? Если индекс уже создан, вы, к сожалению, не сможете изменить количество шардов. Вместо этого нужно создать новый индекс с нужным вам количеством осколков и перенести данные в новый индекс. Есть вероятность, что вам никогда не придется делать этого, если вы разработчик, поэтому обычно вам не нужно беспокоиться об этом. Тем не менее, именно так вы можете изменить количество шардов для индекса, если вам это необходимо.
Итак, подведем итог: шардинг - это способ разделения объема данных индекса на более мелкие части, которые называются шардами. Это позволяет распределить данные между несколькими узлами в кластере, что означает, что вы можете хранить терабайт данных, даже если у вас нет ни одного узла с таким объемом диска. Шардинг также повышает производительность в случаях, когда шарды распределены по нескольким узлам, поскольку поисковые запросы могут быть распараллелены, что позволяет лучше использовать аппаратные ресурсы, доступные вашим узлам.
Распределение документов между шардами (маршрутизация)
Вы узнали, как данные хранятся на потенциально более чем одном узле в кластере, а также как это достигается с помощью шардинга. Но как Elasticsearch узнает, на каком шарде хранить новый документ, и как он найдет его при поиске по ID? Должен быть способ определить это, потому что, конечно, это не может быть случайным. Кроме того, по умолчанию документы должны быть равномерно распределены между узлами, чтобы не получилось так, что один шард содержит гораздо больше документов, чем другой. Поэтому определение того, в каком шарде должен храниться или уже хранится данный документ, называется маршрутизацией.
Чтобы сделать Elasticsearch как можно более простым в использовании, маршрутизация по умолчанию выполняется автоматически, и большинству пользователей не придется вручную разбираться с ней. По умолчанию Elasticsearch использует простую формулу для определения подходящего шарда.
ШАРД = hash(routing) % total_primary_shards
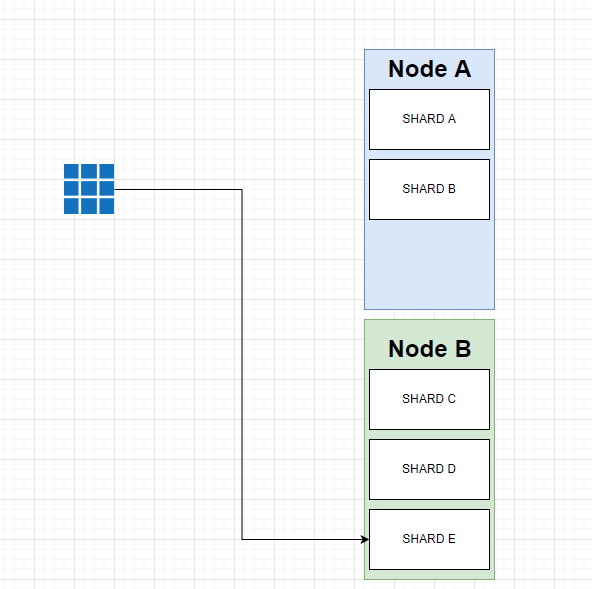
По умолчанию значение "маршрутизации" будет равно ID данного документа. Затем это значение пропускается через функцию хэширования, которая генерирует число, которое можно использовать для деления. Остаток от деления сгенерированного числа на количество первичных шардов в индексе даст номер шарда. Именно так Elasticsearch определяет местоположение конкретных документов. При выполнении поисковых запросов (т.е. не при поиске конкретного документа по ID) процесс происходит иначе, поскольку запрос затем рассылается на все шарды.
Такое поведение по умолчанию обеспечивает равномерное распределение документов между шардами. Поскольку я упомянул, что это "поведение по умолчанию", это, конечно, означает, что его можно изменить. При получении, удалении и обновлении документов вы можете указать пользовательское значение маршрутизации, если хотите изменить способ распределения документов. В качестве примера можно привести ситуацию, когда у вас есть документ для каждого клиента, в этом случае вы можете определить шард на основе страны клиента. В этом случае потенциальная проблема может возникнуть, если большинство ваших клиентов из одной страны, потому что тогда документы не будут равномерно распределены по основным шардам. Причина, по которой я упоминаю об этом, заключается в том, что пользовательская маршрутизация - это немного сложная тема. Хотя ее легко сделать, есть некоторые общие подводные камни и вещи, о которых нужно знать, поэтому ее следует использовать в производственном кластере, только если вы знаете, что делаете. Поэтому сейчас я не буду углубляться в эту тему. Но теперь вы знаете, что такая возможность существует.
Помните, я упоминал, что количество шардов для индекса не может быть изменено после создания индекса? Если принять во внимание формулу маршрутизации, то мы получим ответ на вопрос, почему так происходит. Если бы мы изменили количество осколков, то результат выполнения формулы маршрутизации для документов изменился бы. Рассмотрим пример, когда документ хранился на осколке А, когда у нас было пять осколков, потому что именно таков был результат работы формулы маршрутизации в то время. Предположим, что мы можем изменить количество осколков и что мы изменили его на семь. Если мы попытаемся найти документ по идентификатору, результат формулы маршрутизации может быть другим. Теперь формула может направить нас на шард B, хотя на самом деле документ хранится на шарде A. Это означает, что документ никогда не будет найден, и это вызовет головную боль. Вот почему количество осколков нельзя изменить после создания индекса, поэтому вам придется создать новый индекс и переместить в него документы. Такая же проблема может возникнуть, если вы введете пользовательскую маршрутизацию в существующий индекс, содержащий документы, которые были маршрутизированы с помощью формулы маршрутизации по умолчанию, поэтому будьте осторожны с этим!
Итак, мораль этой истории такова: формула маршрутизации по умолчанию равномерно распределяет документы по первичным осколкам индекса. Маршрутизацию можно изменить, но это может привести к проблемам, поэтому это более сложная тема, которую я не буду сейчас рассматривать. Маршрутизация также является причиной того, что мы не можем изменить количество шардов для индекса, который уже создан, по причинам, которые я только что упомянул.
Хорошая статья, явно самая стоящая для понимая принципов шардинга
Спасибо за обратную связь =)