Apache Kafka - это программное обеспечение для обмена сообщениями, используемое для передачи данных и информации между системами.
Учитывая возможности Kafka, он может поддерживать широкий спектр сценариев использования. В LinkedIn он был создан для сбора метрик об использовании приложений.
Основы Kafka
Очередь сообщений позволяет многим разрозненным приложениям взаимодействовать, посылая друг другу сообщения. Очередь - это очередь объектов, ожидающих обработки - в последовательном порядке, начиная с начала очереди. Приложения, которые читают данные из очереди сообщений, называются "потребителями". Приложения, которые отправляют сообщения в Kafka, называются "производителями".
В платформе данных сообщения могут быть данными, а потребители - программами обработки данных. Эти программы обработки могут быть ориентированы на пакетную обработку, а могут быть программами потоковой обработки в режиме реального времени.

Почему именно Kafka?
- Kafka обладает высокой масштабируемостью. Очень легко добавить большое количество потребителей без ущерба для производительности и надежности. Это потому, что Kafka не отслеживает, какие сообщения в теме были потреблены потребителями. Она просто хранит все сообщения в теме в течение настраиваемого периода времени.
- Kafka также поддерживает различные модели потребления. Вы можете иметь одного потребителя, обрабатывающего сообщения в режиме реального времени, и другого потребителя, обрабатывающего сообщения в пакетном режиме в полностью разделенном режиме.
- Kafka поддерживает возможность получения сообщений от широкого круга производителей.
- Долговечность сообщений в Kafka высокая. Он сохраняет сообщения/события в течение заданного периода времени.
- Kafka линейно масштабируется при больших объемах данных. Добавление дополнительных брокеров/кластеров увеличит пропускную способность или уменьшит задержку.
- Kafka поддерживает отличную интеграцию с другими системами обработки данных. К ним относятся Apache Storm, Spark, NiFi, Flume и т.д. для завершения работы.
Примеры использования Kafka
Обмен сообщениями
Kafka хорошо работает в качестве замены более традиционного брокера сообщений. Брокеры сообщений используются по разным причинам (для разделения обработки и производителей данных, для буферизации необработанных сообщений и т.д.).
Отслеживание активности веб-сайта
Kafka можно использовать для построения конвейера отслеживания активности пользователей в виде набора каналов публикации-подписки в реальном времени. Активность на сайте (просмотры страниц, поиск или другие действия пользователей) может быть опубликована в центральных темах с одной темой для каждого типа активности.
Агрегация журналов
Kafka является заменой решения для агрегации журналов. Агрегация журналов обычно собирает физические файлы журналов с серверов и помещает их в центральное хранилище (файловый сервер или HDFS) для обработки. По сравнению с системами, ориентированными на журналы, такими как Scribe или Flume, Kafka предлагает такую же высокую производительность, более надежные гарантии долговечности благодаря репликации и гораздо меньшую сквозную задержку.
Архитектура Kafka и ее компоненты
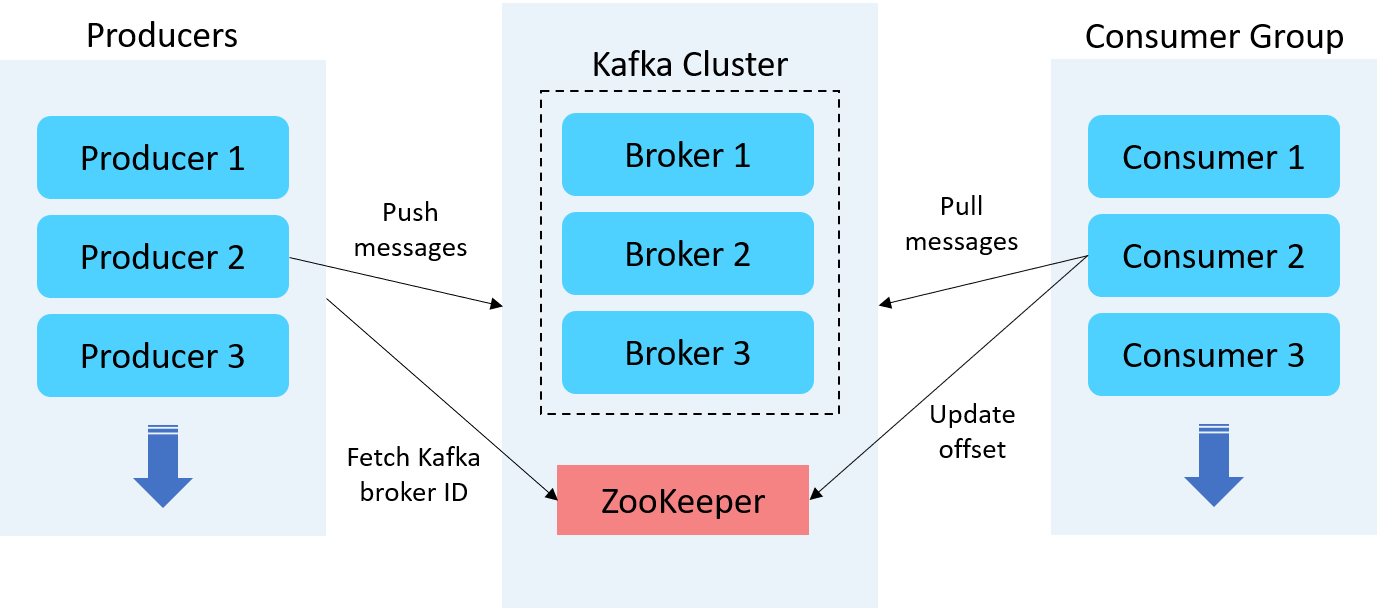
Брокеры Kafka
Брокер Kafka - это сервер, работающий в кластере Kafka (или, говоря иначе, кластер Kafka состоит из нескольких брокеров). Как правило, несколько брокеров работают согласованно, образуя кластер Kafka и обеспечивая балансировку нагрузки, надежное резервирование.
Apache ZooKeeper
Брокеры Kafka используют ZooKeeper для управления и координации работы кластера Kafka. ZooKeeper уведомляет все узлы, когда топология кластера Kafka меняется, в том числе когда брокеры и темы (топики) добавляются или удаляются.
Продюсеры Kafka
Продюсер Kafka служит источником данных, который оптимизирует, записывает и публикует сообщения в одной или нескольких темах (топиках) Kafka. Производители Kafka также сериализуют, сжимают и распределяют данные между брокерами с помощью разделения.
Потребители Kafka
Потребители читают данные, читая сообщения из тем, на которые они подписаны. Потребители принадлежат к группе потребителей. Каждый потребитель в определенной группе потребителей отвечает за чтение подмножества разделов каждой темы, на которую он подписан.
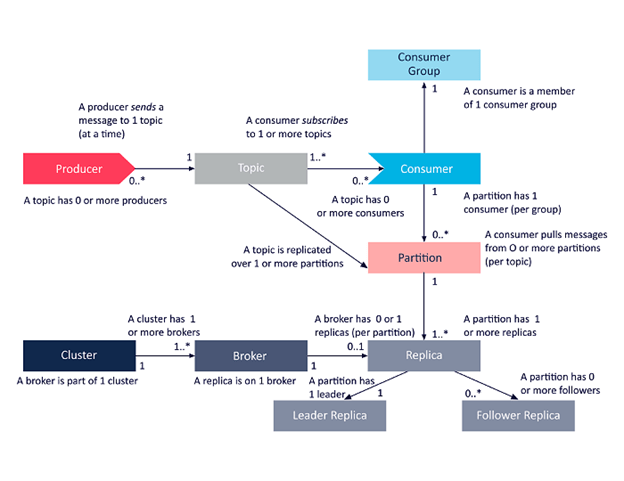
Топики Kafka
Топик Kafka определяет канал, по которому передаются данные. Производители публикуют сообщения в топики, а потребители читают сообщения из топика, на который они подписаны.
Партиции Kafka
В кластере Kafka темы делятся на партиции, а партиции реплицируются между брокерами. Из каждого раздела несколько потребителей могут читать из топика параллельно.
Группа потребителей
Группа потребителей Kafka включает связанных потребителей с общей задачей. Kafka отправляет сообщения из разделов темы потребителям в группе потребителей. В момент чтения каждый раздел читается только одним потребителем в группе.
Фактор репликации тем
Репликация тем необходима для создания отказоустойчивых и высокодоступных развертываний Kafka. Когда брокер выходит из строя, реплики тем на других брокерах остаются доступными, чтобы гарантировать, что данные остаются доступными и что развертывание Kafka избегает сбоев и простоев.
Как обеспечить порядок сообщений
В Kafka порядок может быть гарантирован только в пределах раздела (партиции). Это означает, что если сообщения были отправлены от производителя в определенном порядке, брокер запишет их в партицию, и все потребители будут читать из нее в том же порядке. Поэтому, естественно, в теме с одной партицией легче обеспечить упорядочивание по сравнению с несколькими партициями.
Однако с одной партицией трудно добиться параллелизма и балансировки нагрузки.
Существует несколько способов, с помощью которых мы можем добиться упорядочивания сообщений, параллелизма и балансировки нагрузки одним способом. Давайте посмотрим, как Kafka обрабатывает порядок сообщений с одним брокером/одним партицией и несколькими брокерами/многими партициями.
Порядок сообщений при использовании одного брокера
Порядок сообщений в Kafka хорошо работает для одной партиции. Но с одним разделом трудно добиться параллелизма и балансировки нагрузки.
Давайте создадим топиком (с одной репликой и одной партицией) с именем топика "test":
| 1 | ./kafka-topics.sh --create --zookeeper localhost:2181 --topic test --replication-factor 1 --partitions 1 |
Рассмотрим пример набора данных со схемами row_no, name, transaction_type и amount, как показано ниже:
| 1 2 3 4 5 | 0001,Test1,credit,10000 0002,Test2,debit,20000 0003,Test3,credit,30000 0004,Test4,debit,40000 0005,Test5,debit,50000 |
Kafka поставляется с клиентом командной строки, который будет принимать данные из файла или стандартного ввода и отправлять их в виде сообщений в кластер Kafka. По умолчанию каждая строка будет отправлена как отдельное сообщение.
Давайте опубликуем приведенный выше пример набора данных в нашей новой топика test:
| 1 2 3 4 5 6 | ./kafka-console-producer.sh --topic test --bootstrap-server localhost:9092 >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000 |
Порядок будет получен такой же, как и выше для одного топика.
| 1 2 3 4 5 6 | ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000 |
Порядок сообщений при использовании нескольких брокеров
Существует три метода, с помощью которых мы можем сохранить порядок сообщений внутри разделов в Kafka. У каждого метода есть свои плюсы и минусы.
Метод 1: Round Robin или Spraying
Метод 2: Хеширование ключевых разделов
Метод 3: Пользовательский разделитель
Метод 1: Round Robin или Spraying (по умолчанию)
В этом методе разделитель будет посылать сообщения всем партициям по кругу, обеспечивая сбалансированную нагрузку на сервер.
Для примера создадим топик (с тремя репликами и тремя партициями) с именем топика "test2":
| 1 | ./kafka-topics.sh --create --zookeeper localhost:2181 --topic test --replication-factor 3 --partitions 3 |
Опубликуем тот же набор данных в новой топике test2:
| 1 2 3 4 5 6 | /.kafka-console-producer.sh --topic test2 --bootstrap-server localhost:9092 >0001,Test1,credit,10000 >0002,Test2,debit,20000 >0003,Test3,credit,30000 >0004,Test4,debit,40000 >0005,Test5,debit,50000 |
Давайте создадим потребителя, который будет получать сообщения из Kafka:
| 1 2 3 4 5 6 | ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test2 --from-beginning >0004,Test4,debit,40000 >0001,Test1,credit,10000 >0003,Test3,credit,30000 >0002,Test2,debit,20000 >0005,Test5,debit,50000 |
Давайте разберемся, что происходит под капотом. Есть три раздела (A, B и C). Раздел B работает быстро благодаря низкой сетевой и системной задержке, и сообщения, отправленные на него, были получены первыми. Затем идет раздел C, за которым следует A.
Этим методом достигается параллелизм и балансировка нагрузки, но не удается сохранить общий порядок, однако порядок внутри раздела сохраняется. Это метод по умолчанию, и он не подходит для некоторых бизнес-сценариев. Если дебетовая транзакция произойдет раньше кредитной, то это будет неясно для бизнес-пользователей, которые потребляют сообщения.
Для того чтобы преодолеть описанные выше сценарии и сохранить порядок сообщений, давайте попробуем другой подход.
Метод 2: Хеширование ключевых разделов
В этом методе мы можем создать ProducerRecord, указать ключ сообщения, вызвав new ProducerRecord (имя топика, ключ сообщения, сообщение).
Разделитель по умолчанию будет использовать хэш ключа, чтобы гарантировать, что все сообщения для одного и того же ключа попадут к одному и тому же производителю. Это самый простой и наиболее распространенный подход. Это тот же метод, который использовался. Для хеширования используется операция модуляции.
Hash(Key) % Количество партиций -> Номер партиции
Однако простая отправка строк текста приведет к сообщениям с нулевыми ключами. Чтобы отправлять сообщения с ключами и значениями, мы должны установить свойства parse.key и key.separator в командной строке при запуске производителя.
Ниже приведен фрагмент кода для метода хэширования, который устанавливает свойство parse.key в true, а для key.separator задает ":".
В приведенном ниже примере сообщений ключами являются key1, key2, а значениями - value1, value2.
| 1 2 3 4 5 6 | -- broker-list localhost:9092 \ -- topic topic-name \ -- property "parse.key=true" \ -- property "key.separator=:" key1:value1 key2:value2 |
Давайте создадим топик (с тремя репликами и тремя партициями) с именем темы test1:
| 1 | ./kafka-topics.sh --create --zookeeper localhost:2181 --topic test1 --replication-factor 3 --partitions 3 |
И опубликуем несколько сообщений в топике test1 с ключевым значением для всех записей:
| 1 2 3 4 5 6 | ./kafka-console-producer.sh --topic test1 --bootstrap-server localhost:9092 --property "parse.key=true" --property "key.separator=:" >0001:0001,Test1,credit,10000 >0002:0002,Test2,debit,20000 >0001:0001,Test3,credit,30000 >0002:0002,Test4,debit,40000 >0001:0001,Test5,debit,50000 |
Как видно ниже, порядок сообщений внутри ключей сохраняется.
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1 --from-beginning
| 1 2 3 4 5 6 | ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test1 --from-beginning >0002:0002,Test2,debit,20000 >0002:0002,Test4,debit,40000 >0001:0001,Test1,credit,10000 >0001:0001,Test3,credit,30000 >0001:0001,Test5,debit,50000 |
Брокер назначает ключ 0001 для раздела A (раздел с высокой задержкой) и ключ 0002 для раздела B (раздел с низкой задержкой), используя метод хэширования ключей. Потребитель потребляет сообщение, основываясь на значении ключа в заказе.
С помощью этого метода мы можем поддерживать порядок сообщений в пределах ключа.
Но недостатком этого метода является то, что он использует случайное значение хэширования для передачи данных в назначенный раздел, и это приводит к перегрузке данных в один раздел.
Метод 3: Пользовательский разделитель
Мы можем написать собственную бизнес-логику, чтобы решить, какое сообщение должно быть отправлено в тот или иной раздел. При таком подходе мы можем упорядочить сообщения в соответствии с нашей бизнес-логикой и одновременно добиться параллелизма.

Основные выводы
- Одной из важнейших функций Kafka является балансировка нагрузки на сообщения и гарантированное упорядочивание в распределенном кластере для достижения параллелизма.
- Использование большего количества разделов приводит к увеличению пропускной способности и задержки. Однако это может привести к накладным расходам на обслуживание.
- Используя раздел с хэширующим ключом, мы можем доставлять сообщения с одинаковым ключом по порядку, отправляя их в один и тот же раздел. Данные внутри раздела будут храниться в том порядке, в котором они были записаны. Поэтому данные, прочитанные из раздела, будут прочитаны по порядку для этого раздела с ключом производителя.
- Используя Пользовательский разделитель, мы можем маршрутизировать сообщения, используя произвольные бизнес-правила.