Брокер Kafka - это не более и не менее, чем JVM-процесс, запущенный на машине, который обслуживает запросы на хранение/выборку данных от клиентов, т.е. производителей (генераторы) и потребителей.
Сами данные хранятся в определенных каталогах, настроенных с помощью log.dirs, обычно это список дисковых точек монтирования данного Брокера. Вы, вероятно, уже слышали, что дисковый ввод-вывод медленный, но если Kafka использует диск для хранения сегментов журнала, то как же он настолько производителен? Давайте проанализируем это.
В этом посте мы рассмотрим, как работает традиционная передача данных, что такое оптимизация Zero Copy и как Kafka выигрывает от нее в сочетании с Page Cache.
Традиционная передача данных
Чтобы прочитать файл с диска и отправить его по сети, традиционная передача данных потребует четырех контекстных переключений между пользовательским режимом и режимом ядра, в результате чего данные будут скопированы четыре раза.
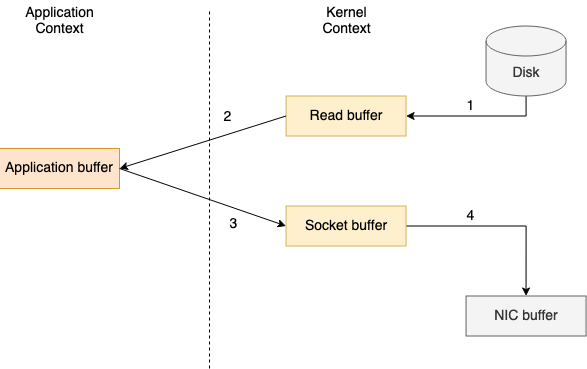
Процесс передачи данных состоит из четырех следующих шагов:
- Вызов File.read(...) переключает контекст из пользовательского режима в режим ядра, и копирование данных выполняется механизмом прямого доступа к памяти (DMA), который считывает содержимое файла и сохраняет его в буфере адресного пространства ядра (буфер чтения);
- Данные копируются из буфера пространства ядра в буфер пользователя, в результате чего вызов File.read(...) возвращается и контекст переключается обратно в режим пользователя;
- Вызов Socket.send(...) заставляет контекст переключиться в режим ядра, и снова выполняется третье копирование данных из буфера пользователя в буфер ядра;
- Вызов Socket.send(...) возвращается и производит последнее переключение контекста в режим пользователя. Четвертая копия данных выполняется механизмом DMA, передавая их из буфера ядра (буфера сокета) в буфер контроллера сетевого интерфейса (NIC) для отправки по сети.
Если размер запрашиваемых данных больше, чем размер буфера ядра, то между пространствами ядра и пользователя будет еще больше копий. Оптимизация нулевых копий уменьшает эти избыточные копии данных.
Передача данных с нулевым копированием
Оптимизация нулевой копии заключается в удалении второй и третьей копий данных, в результате чего данные передаются непосредственно из буфера чтения в буфер сокета.
В UNIX и различных версиях Linux эта оптимизированная передача данных обрабатывается системным вызовом sendfile(), который копирует данные между двумя файловыми дескрипторами.
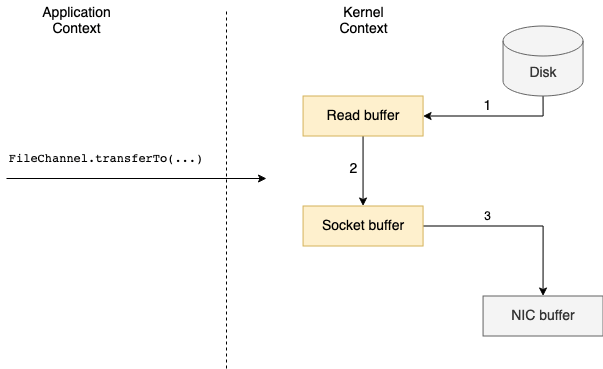
Приложение на базе JVM должно использовать метод transferTo() FileChannel, который под капотом вызывает системный вызов в случае, если нулевое копирование поддерживается базовой операционной системой.
Переключение контекста сокращается с четырех до двух, во время вызова FileChannel.transferTo(...) и его возврата. Что касается копий данных, они могут быть сокращены с четырех до двух или дерева, в зависимости от того, поддерживает ли базовая сетевая карта операции сбора (функция доступна на ядрах Linux версии 2.4 и выше).
Когда операции сбора не поддерживаются, необходимо выполнить копирование из буфера чтения в буфер сокета. Однако, поскольку оба они находятся в ядре, это обрабатывается механизмом DMA.
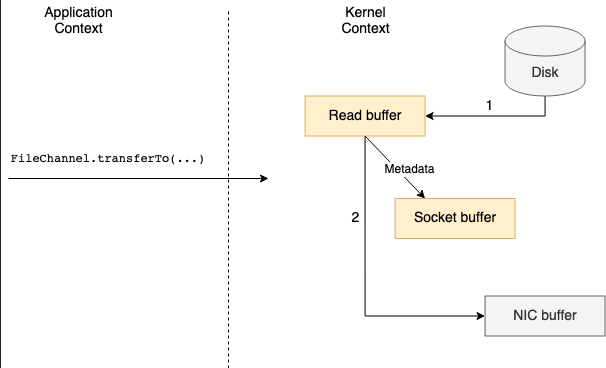
Если сетевая карта поддерживает операции сбора, в буфер сокета записываются только дескрипторы с информацией о местоположении и длине данных. Данные передаются непосредственно из буфера чтения в сетевую карту.
Передача данных Kafka
Kafka в значительной степени использует Page Cache операционной системы для хранения недавно использованных данных, поэтому важно иметь значительный объем памяти (RAM) на машине брокера.
Page Cache находится в неиспользуемых частях оперативной памяти и используется для хранения страниц данных, которые были недавно прочитаны с диска или записаны на него.
Еще одним важным аспектом дизайна Kafka является то, что производитель, брокер и потребитель используют стандартный формат двоичных сообщений. Это означает, что данные передаются от Производителя к Брокеру и хранятся как есть, без каких-либо изменений. Эти же двоичные данные затем отправляются Потребителям, когда они запрашиваются.
Когда Брокер получает данные от Производителя, они немедленно записываются в постоянный журнал в файловой системе, однако это не означает, что они будут сброшены на диск. Данные будут переданы в страничный кэш ядра, и операционная система сама решит, когда произойдет очистка, то есть в зависимости от настроенных параметров ядра vm.dirty_ratio, vm.dirty_background_ratio и vm.swappiness.
Теперь, когда мы рассмотрели, что такое оптимизация нулевой копии, стандартизированный формат двоичных сообщений Kafka и его дизайн с использованием кэша страниц, мы можем полностью понять приведенные ниже выдержки из документации Kafka:
- Мы ожидаем, что общим примером использования будет несколько потребителей по одной теме. Используя вышеуказанную оптимизацию нулевого копирования, данные копируются в pagecache ровно один раз и повторно используются при каждом потреблении вместо того, чтобы храниться в памяти и копироваться в пространство пользователя при каждом чтении. Это позволяет потреблять сообщения со скоростью, приближающейся к пределу сетевого соединения.
- Такое сочетание pagecache и sendfile означает, что на кластере Kafka, где потребители в большинстве своем уже набраны, вы не увидите никакой активности чтения на дисках, поскольку они будут обслуживать данные полностью из кэша.
Другими словами, если у нас есть 3 потребителя (с разными group.id), запрашивающих данные по определенной теме, на брокере данные будут скопированы с диска в кэш страниц только один раз и отправлены по сети каждому потребителю. Если это были недавно созданные сообщения для данной темы, то считывание с диска не потребуется, так как "теплые" данные все еще будут присутствовать в кэше страниц. Это возможно потому, что запись и чтение для раздела темы обрабатываются только "лидером" раздела, а записи производителей записываются в сегментный файл, доступный только для приложений. Это означает, что частые операции чтения и записи одной и той же темы будут выполняться быстро, поскольку сегментный файл (файлы) будет находиться в страничном кэше.
SSL и нулевое копирование
Поскольку SSL позволяет шифровать данные на лету, мы больше не отправляем те же данные, которые хранятся на Broker. Это означает, что при включенном SSL теряется оптимизация нулевой копии, поскольку Брокеру необходимо расшифровывать и шифровать данные. В документации Kafka нет упоминания об этом, но это было подтверждено разработчиками Kafka. Ожидается, что при включенном SSL будет наблюдаться некоторое снижение производительности.