В Elasticsearch поисковый запрос может быть как простым, состоящим из одного документа, так и большим и сложным, состоящим из миллионов записей.
Это краткое руководство научит вас обрабатывать документы, полученные в результате поискового запроса, с помощью Scroll API.
![]()
Следует отметить, что Scroll документов с помощью API не рекомендуется для запросов в реальном времени. В основном он полезен для обработки обширных коллекций документов.
Базовое использование
В этом примере мы будем использовать индекс kibana_sample_data_flights. Данные выборки можно найти на странице начала работы с Kibana.
Предположим, мы хотим получить количество рейсов, на которых цена билета была больше 500 и меньше 1000, мы можем выполнить запрос следующим образом:
| 1 2 3 4 5 6 7 8 9 10 11 12 | GET /kibana_sample_data_flights/_search { "query": { "range": { "A": { "gte": 500, "lte": 1000, "boost": 2 } } } } |
Выполнив приведенный выше запрос, мы должны получить все документы в указанном диапазоне стоимости билета.
Ниже приведен пример вывода:
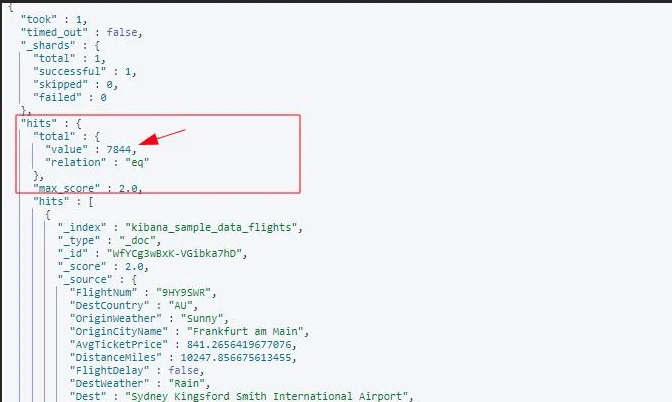
Как видно из приведенного выше результата, за один запрос мы получаем более 7800 результатов.
Допустим, мы хотим просмотреть только одну запись за раз, а не все 7844. Мы можем сделать это, используя параметры from и size, как показано в запросе ниже:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | GET /kibana_sample_data_flights/_search { "from": 0, "size": 1, "query": { "range": { "AvgTicketPrice": { "gte": 500, "lte": 1000, "boost": 2 } } } } |
В приведенном выше примере мы используем параметр from, который определяет, с какого индекса следует начинать выборку записей. Поскольку индексирование в Kibana начинается с 0, мы задаем его в качестве начального значения индекса.
Параметр size задает максимальное количество записей, которые нужно показать на одной странице.
Пример результатов приведен ниже:

Как видно из приведенного результата, мы получаем только один документ из общего числа 7844.
Чтобы перейти к следующему документу, мы начинаем с 1, а не с 0:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | GET /kibana_sample_data_flights/_search { "from": 1, "size": 1, "query": { "range": { "AvgTicketPrice": { "gte": 500, "lte": 1000, "boost": 2 } } } } |
В результате из результатов поиска будет получен следующий документ.
При использовании параметров from и size, Elasticsearch ограничит вас только 10 000 документов.
Scroll API
На этом этапе нам пригодится Scroll API. С его помощью мы можем получить обширную коллекцию документов с помощью одного запроса.
Для работы с Scroll API требуется идентификатор scroll_id, который можно получить, указав в запросе аргумент scroll.
Аргумент scroll должен указывать, как долго сохраняется поисковый контекст.
Рассмотрим его использование на примере.
Первым делом необходимо получить идентификатор scroll_id, что можно сделать, передав параметр scroll, за которым следует длительность существования поискового контекста.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | POST /kibana_sample_data_flights/_search?scroll=10m { "size": 100, "query": { "range": { "AvgTicketPrice": { "gte": 500, "lte": 1000, "boost": 2 } } } } |
В приведенном выше примере запроса мы задаем параметр scroll с контекстом поиска 10 минут. Затем мы указываем количество записей, которые необходимо получить на одной странице, и запрос, которому необходимо соответствовать.
Ответ на запрос должен содержать идентификатор scroll_id, который мы можем использовать в Scroll API, и первые 100 документов, соответствующих указанному запросу.

Чтобы получить следующую партию из 100 записей, мы используем Scroll API, включая идентификатор из приведенного выше ответа.
| 1 2 3 4 5 | GET /_search/scroll { "scroll": "10m", "scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFko5WGQ3VTBOUzVlW" } |
В приведенном выше запросе мы указываем, что хотим использовать Scroll API, а затем контекст поиска. Это дает команду Elasticsearch обновить поисковый контекст и поддерживать его в актуальном состоянии в течение 10 минут.
Далее мы передаем идентификатор scroll_id, полученный из предыдущего запроса, и получаем последующие 100 документов.
Заключение
Scroll API может пригодиться, когда необходимо получить документы, количество которых превышает 10 000. Несмотря на свою функциональность, Scroll API имеет ряд недостатков, устраняемых другими методами пагинации, такими как search_after.